Soccer Field Detection

Video tracking plays a vital role in modern sports analytics. Analysts and scientists use algorithms like YOLO to identify players and balls in game films to generate insights about players' performances. Because the game film is, in most cases, not uniform, a few challenges come with tracking humans in videos. Most videos include people outside the field of play, such as staff, substitutes, and fans. This can muddy the data and make it harder to track individual players or create anomalous data. In order to account for this, it is helpful to mask out the area surrounding the playing field as a preprocessing step. To achieve this goal, I developed a convolutional neural network to take individual images from a video and identify the playing field. Using this model, analysts could quickly isolate only the data they intend to use.
To create a training set, I developed a program allowing users to manually define the playing field on an image of a soccer match. The images came from the Islamic Azad University Football Dataset. The dataset contains a collection of images captured from soccer game broadcasts. The program isolates only the images of the correct aspect ratio and shows them to the user, who selects the boundaries of the playing surface. If the image is not of a soccer field, i.e., a picture of a lineup card, then the user can have that image removed from the training set. With this program, I manually created 3,600 images which I used to train the model.
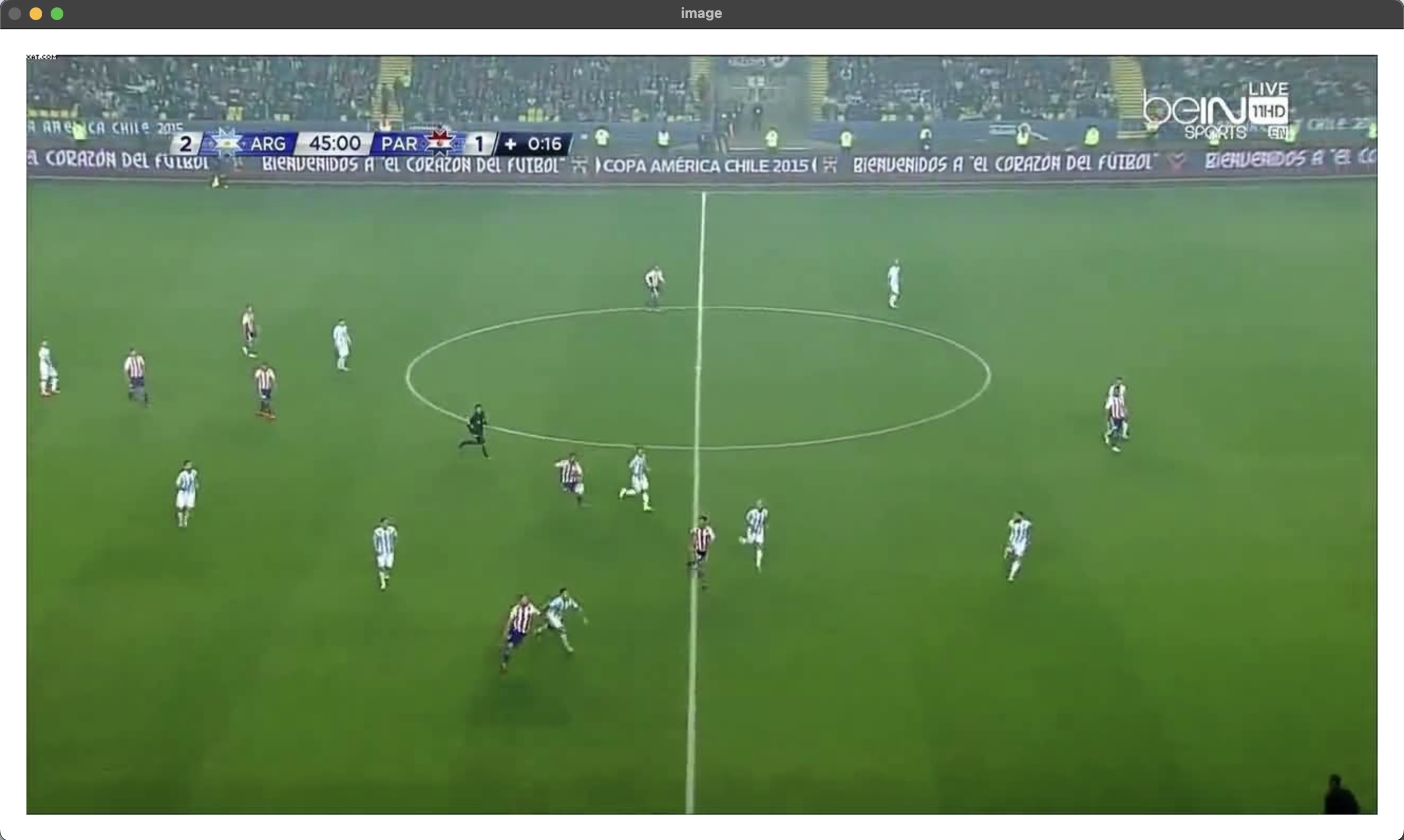
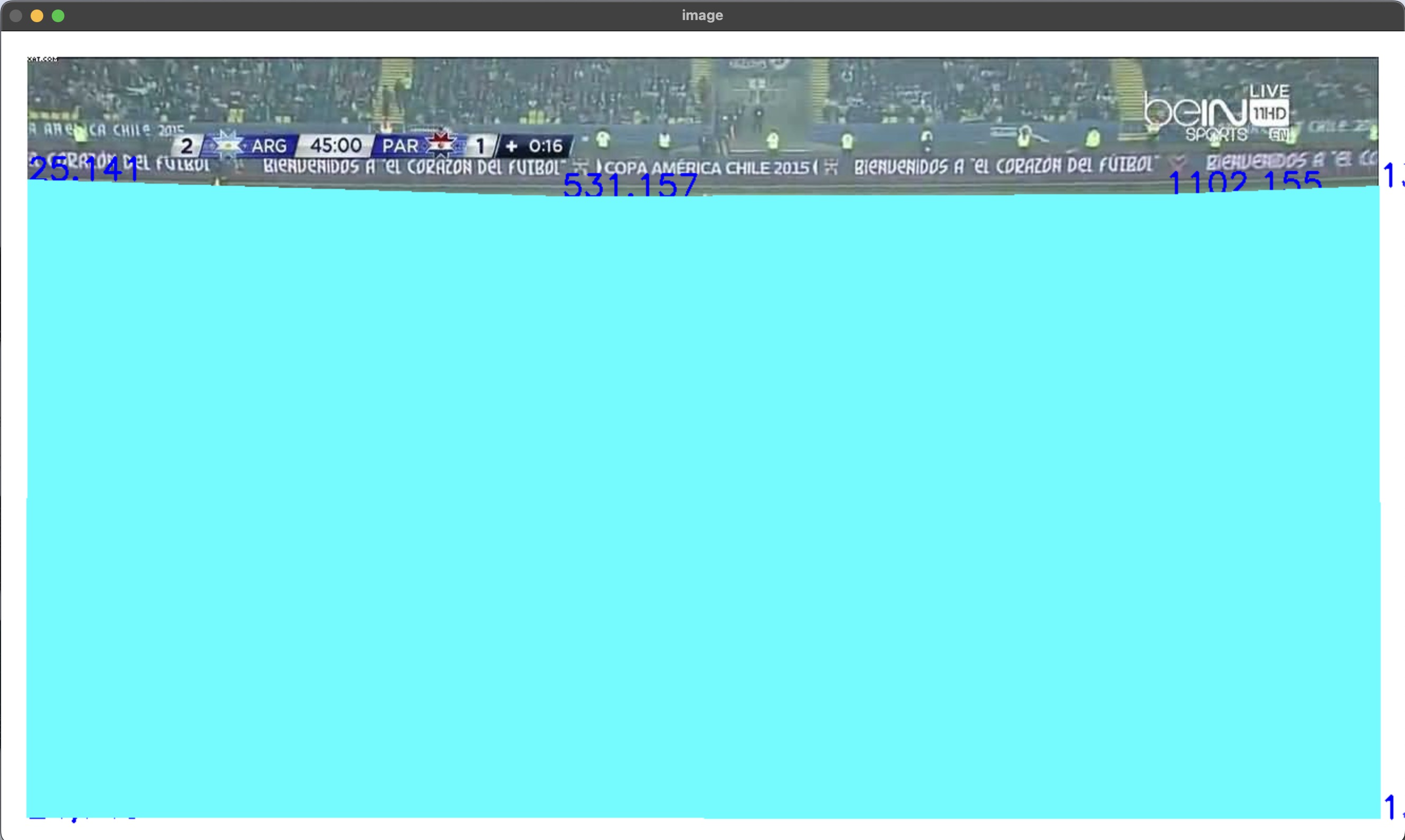
The model is a PyTorch convolutional neural network with two convolutional layers and three fully connected linear layers. The model trains using binary cross entropy loss and reports losses as low as .10. This could be improved dramatically by creating more training data. I have also written a short script that allows users to implement the model and mask out areas, not in the playing surface of their images. The function allows users to input a padding zone so they can be more confident that they are not excluding any of the areas of play.
In its current form, the model works to a satisfactory level but could easily be improved with more training data. If you are interested in helping manually create the training data, please reach out.
To see the data or code go here:
Kaggle GitHubReferences:
Zanganeh, A., Jampour, M., & Layeghi, K. (2022). IAUFD: A 100K images dataset for Automatic Football Image/video analysis. IET Image Processing, 16(12), 3133–3142. https://doi.org/10.1049/ipr2.12543